
[ad_1]
I blocked two of our position internet pages employing robots.txt. We shed a posture in this article or there and all of the featured snippets for the pages. I expected a whole lot a lot more effect, but the globe did not end.
Warning
I do not suggest accomplishing this, and it’s fully doable that your success may be diverse from ours.
I was seeking to see the impression on rankings and traffic that the removal of written content would have. My idea was that if we blocked the pages from currently being crawled, Google would have to depend on the connection signals by yourself to rank the material.
Nonetheless, I really do not assume what I observed was really the effect of getting rid of the information. Possibly it is, but I simply cannot say that with 100% certainty, as the effect feels way too modest. I’ll be functioning another check to ensure this. My new strategy is to delete the content from the webpage and see what happens.
My operating concept is that Google may possibly however be employing the content it employed to see on the website page to rank it. Google Research Advocate John Mueller has confirmed this conduct in the past.
So considerably, the examination has been working for almost five months. At this stage, it does not seem like Google will halt ranking the website page. I suspect, immediately after a when, it will probable prevent trusting that the material that was on the web site is even now there, but I haven’t found evidence of that occurring.
Maintain looking at to see the exam setup and effect. The principal takeaway is that accidentally blocking pages (that Google already ranks) from getting crawled utilizing robots.txt probably is not heading to have considerably affect on your rankings, and they will probably still present in the lookup results.
I selected the same internet pages as applied in the effects of url research, other than for the short article on Search engine marketing pricing due to the fact Joshua Hardwick experienced just current it. I experienced noticed the effects of removing the hyperlinks to these content and preferred to check the impression of taking away the material. As I reported in the intro, I’m not sure that’s in fact what took place.
I blocked these two pages on January 30, 2023:
These lines had been additional to our robots.txt file:
Disallow: /web site/leading-bing-searches/Disallow: /website/major-youtube-searches/
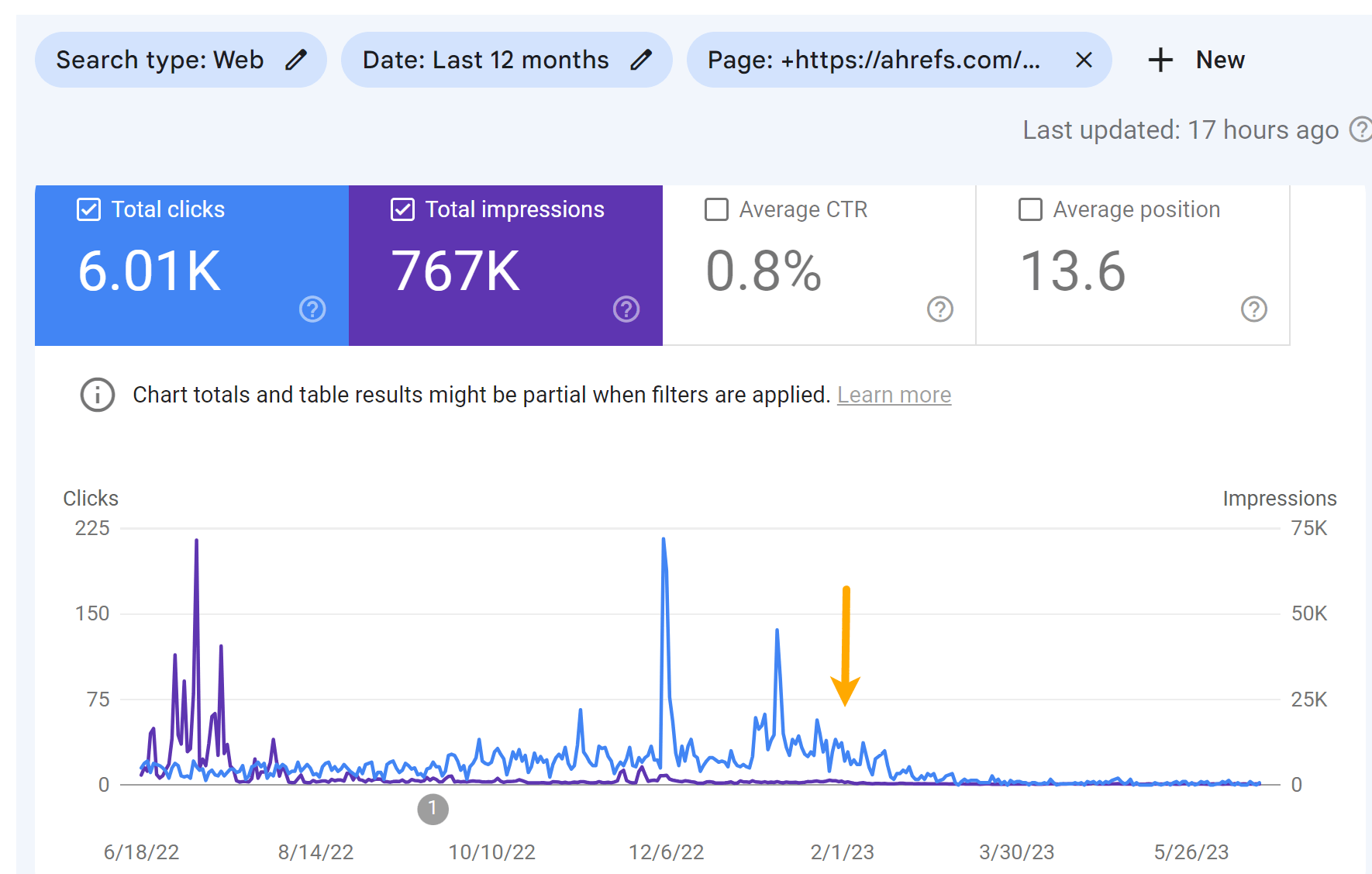
As you can see in the charts underneath, both equally web pages missing some visitors. But it did not result in a great deal adjust to our visitors estimate like I was expecting.
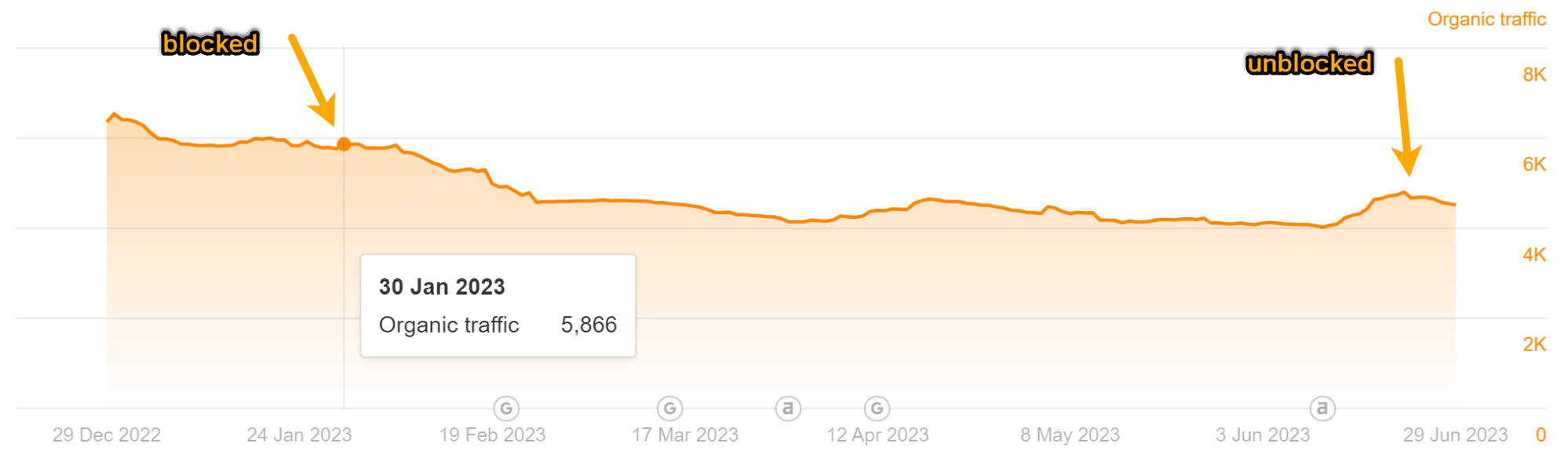
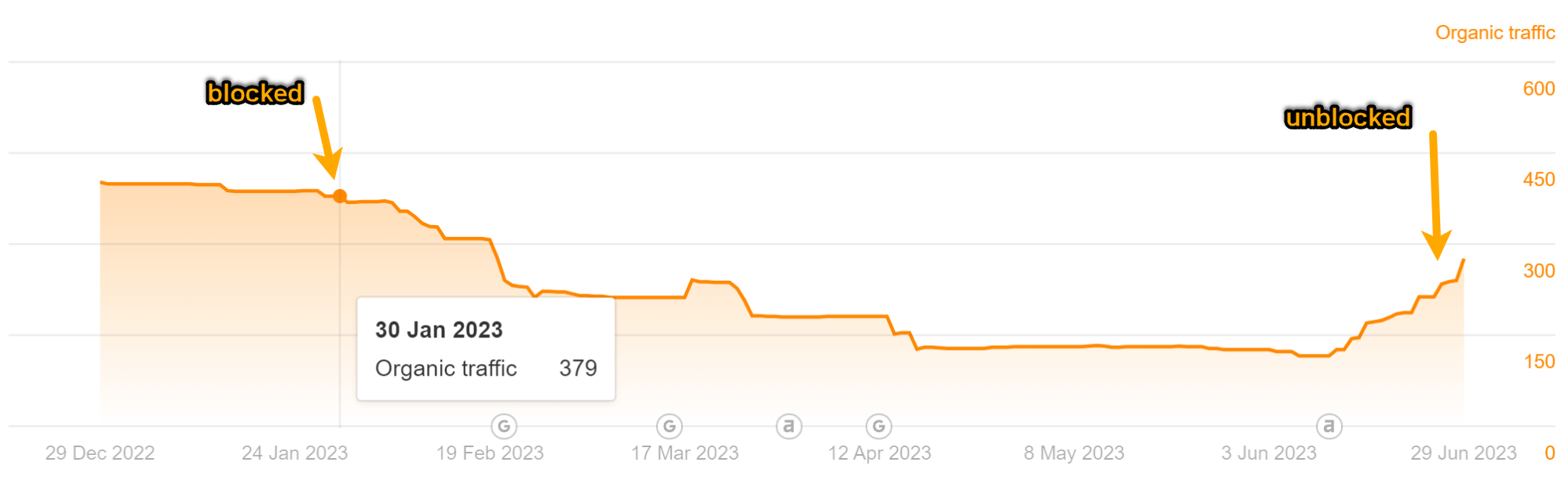
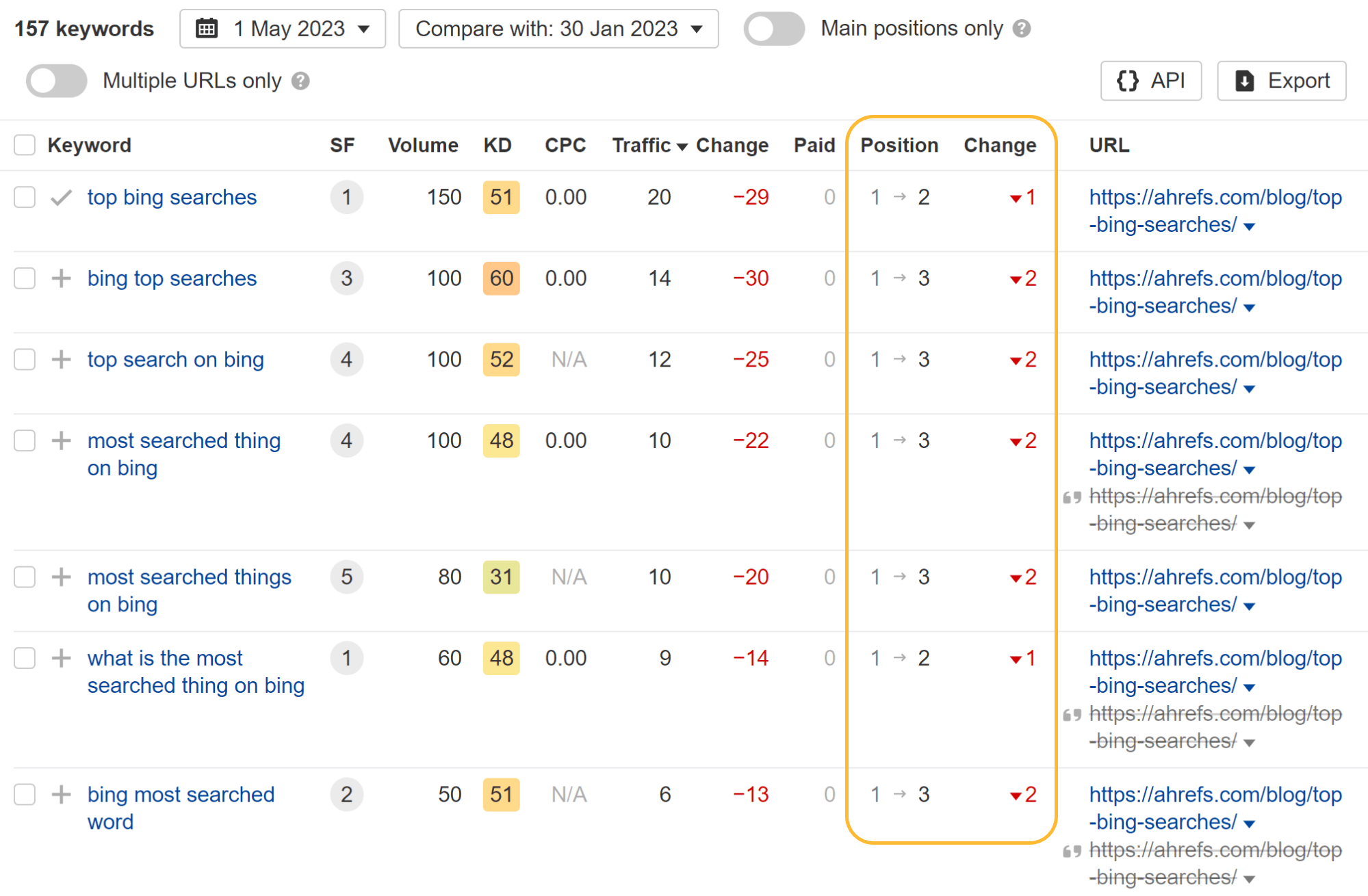
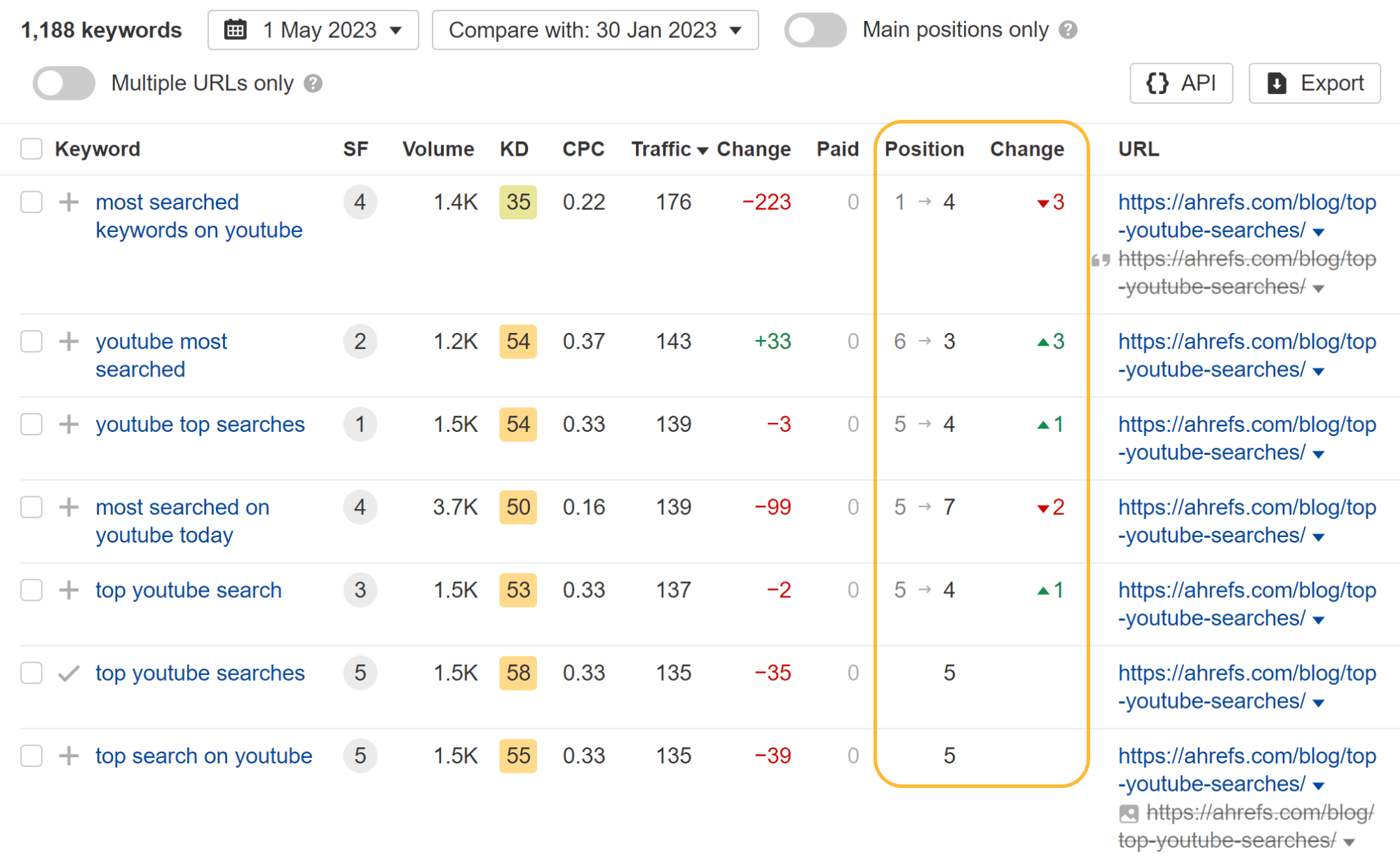
Wanting at the individual keyword phrases, you can see that some keywords and phrases shed a placement or two and many others in fact acquired position positions whilst the website page was blocked from crawling.
The most attention-grabbing factor I noticed is that they shed all showcased snippets. I guess that having the webpages blocked from crawling manufactured them ineligible for featured snippets. When I later on eradicated the block, the report on Bing searches quickly regained some snippets.
The most noticeable impact to the web pages is on the SERP. The webpages shed their customized titles and exhibited a concept saying that no data was available as an alternative of the meta description.
This was predicted. It comes about when a web site is blocked by robots.txt. Moreover, you’ll see the “Indexed, nevertheless blocked by robots.txt” standing in Google Look for Console if you inspect the URL.
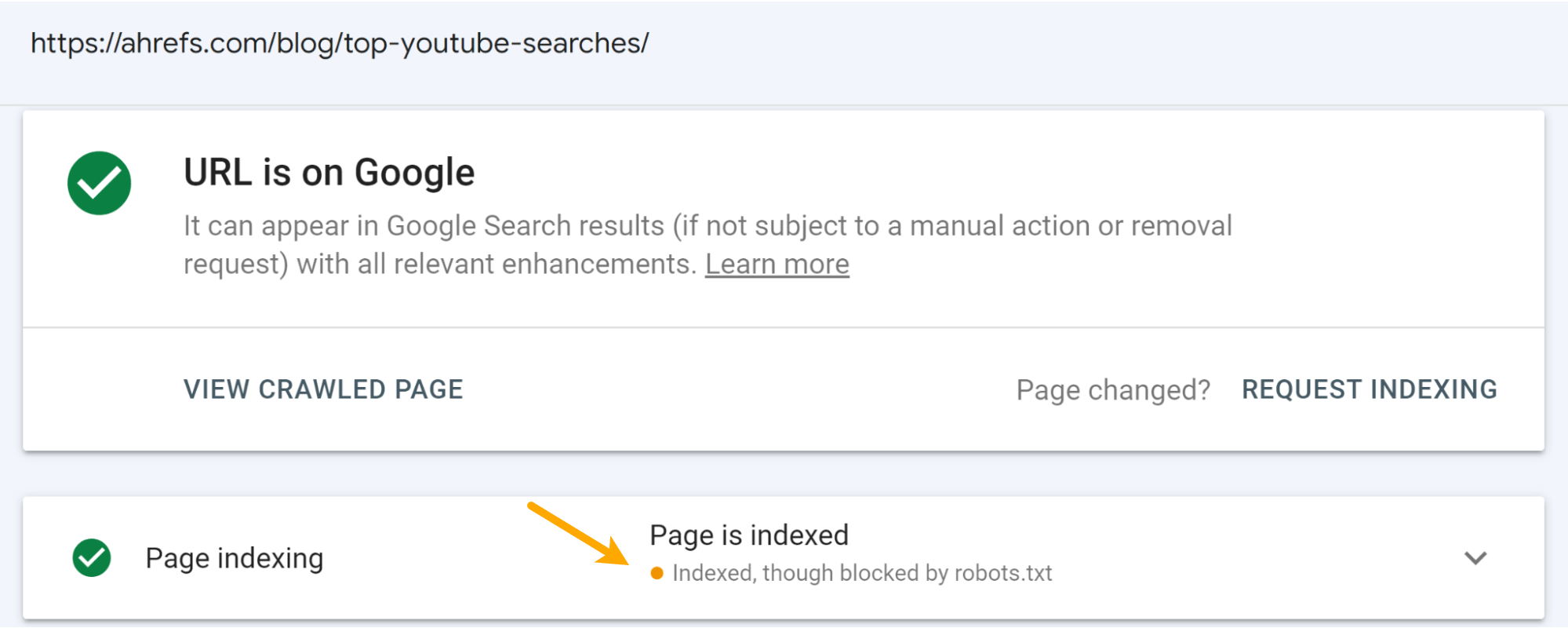
I think that the concept on the SERPs hurt the clicks to the internet pages additional than the rating drops. You can see some drop in the impressions, but a greater fall in the selection of clicks for the articles.
Targeted visitors for the “Top YouTube Searches” report:
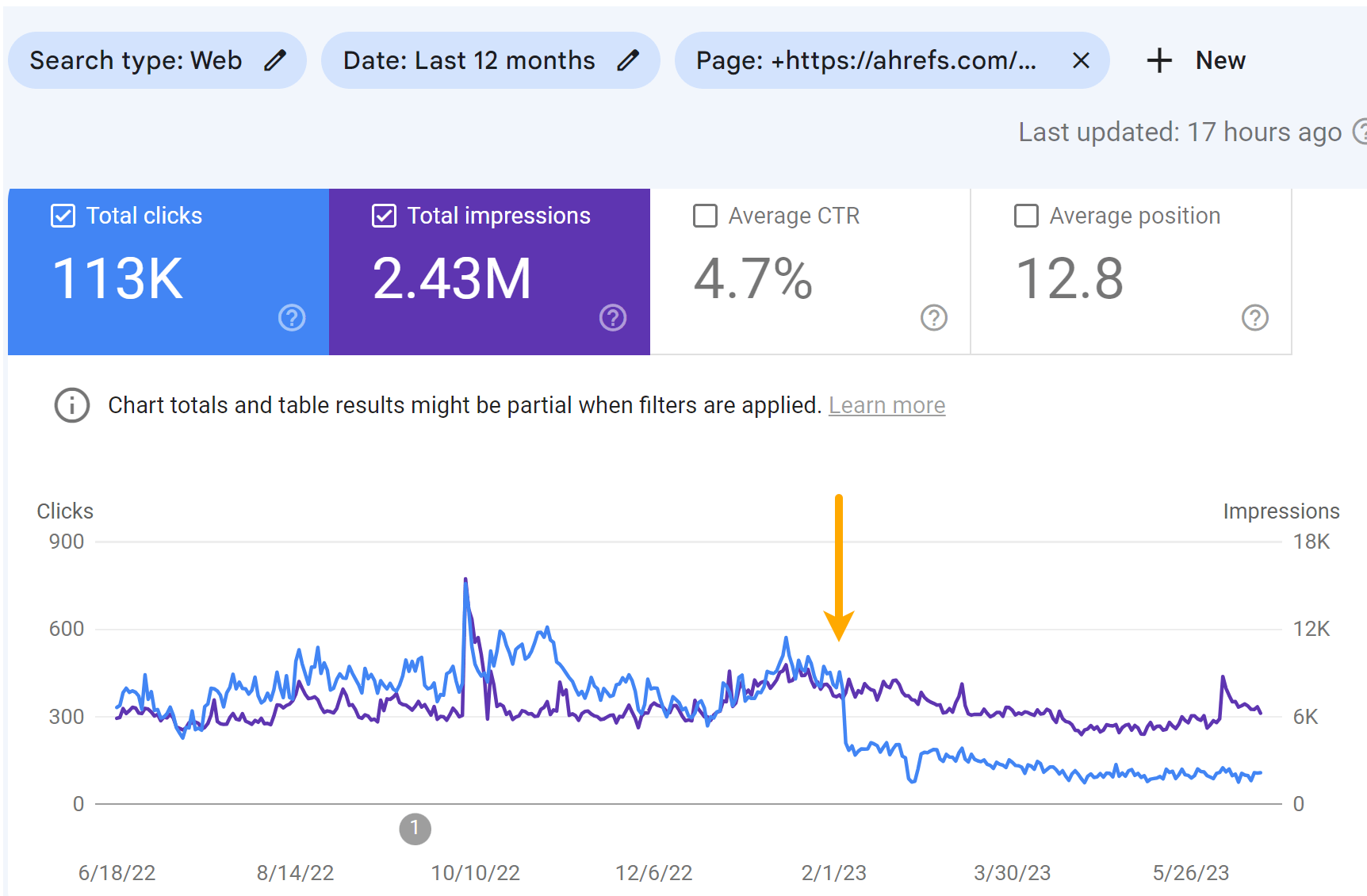
Site visitors for the “Top Bing Searches” post:
Closing ideas
I do not consider any of you will be surprised by my commentary on this. Do not block internet pages you want indexed. It hurts. Not as negative as you may possibly feel it does—but it still hurts.
[ad_2]
Source hyperlink








{kind=link}