[ad_1]

Artificial Intelligence (AI) has greatly evolved in many areas, including speech and picture recognition, autonomous driving, and natural language processing. However, generative AI, a relatively new area, has become a game-changer in data generation and content creation. Generative AI develops new data that resembles existing data while adding distinctiveness to it using machine learning techniques. Generative AI models have created realistic graphics, movies and music, among other content. By facilitating the quick and efficient development of new content and data, this technology can potentially transform various industries, from entertainment to healthcare.
Generative AI uses a variety of models, including Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Autoregressive Models, to create new data. To produce fresh data, each of these models employs a distinct approach.
Generative artificial intelligence has a wide range of uses. For instance, generative AI can be applied in image generation to produce lifelike visualizations of hypothetical items, giving designers a glimpse of how their designs could appear. It is capable of producing original musical compositions as well as soundtracks for video games and movies. It has the potential to transform industries like entertainment, art and design by opening up new avenues for human-machine cooperation.
The key features of generative AI are:
Creativity: Large datasets are employed by generative AI models to learn patterns and features that are later applied to create new data that resembles the training data. These models can be trained using various data, including text, photos, videos, music, and audio files. Generative AI is a potent tool for content creation and data generation since it can generate new data with some originality by learning from existing data. For instance, while creating images, a generative AI model may be trained on a dataset of thousands of photographs of animals to identify the traits shared by the many animal species. Then, using this information, it is possible to create new, lifelike images of creatures that do not exist.
Flexibility: A wide variety of content, like images, films, music and text, can be produced using generative AI models. This is possible because deep learning, the foundational technique for generative AI, can be used to process various types of data.
Scalability: Generative AI models can be scaled up or down to generate a vast amount of data rapidly and effectively. Due to deep learning’s parallel computing capabilities, generative AI models may be trained and used on high-performance computing platforms, enabling scalability. This implies that the models have enormous parallel data processing capacity, which can greatly accelerate the generating process.
Creating lifelike images: Generative AI has made it possible to produce data that is highly realistic and similar to the original data. Deep neural networks, which can recognize intricate patterns and connections in data, are used to accomplish this. A generative AI model can learn the statistical characteristics of the data by being trained on a sizable collection of real-world data, and the model can then produce new data that closely mimics the original data. For instance, a generative AI model may create new, extremely realistic photos of faces that closely resemble the original photographs after being trained on a dataset of face images.
Adaptability: Generative AI models can be adapted to different tasks, such as an image or text generation, depending on the data type they are trained on. A model trained on a large dataset of text may be used for tasks requiring the generation of texts, whereas a model trained on a large dataset of photos could be used for projects requiring the creation of images. Because generative AI models are built to discover patterns and relationships in the data they are trained on, they can be flexible. The model can learn to produce new instances comparable to the input data by changing its parameters and fine-tuning it on new data. The ability of generative AI models to adapt to diverse requirements is one of the factors that makes them so powerful and useful in various applications, from creating art and music to creating realistic simulations for scientific research.
Continual learning: Continuous learning, or incremental learning, allows generative AI models to be trained on fresh data over time. This is a crucial component of generative AI models since it enables them to develop as they are presented with fresh examples and produce more accurate data. Because generative AI models are built to discover patterns and relationships in the data they are trained on, continuous learning is made feasible. When introduced to fresh examples, they can update their internal representations to include relevant information. As a result, the model can adjust to changes in the fundamental distribution of the data and produce increasingly accurate data over time. Continuous learning is helpful in applications like natural language processing and a picture identification, where the data is always changing or evolving. The model can be up-to-date and produce high-quality outputs even when input data changes by regularly training on fresh data.
There are several types of generative AI models, some of which are:
Variational Autoencoders (VAE): Variational Autoencoders (VAE) is a generative artificial intelligence model that can identify the underlying structure of input data and produce new examples comparable to the original data. An input data point can be encoded into a latent variable, a lower-dimensional representation, and then decoded back into the original input using a particular neural network. An encoder and a decoder are the primary parts of a VAE’s basic architecture.
An input data point is passed via the encoder, which converts it into a latent space distribution. Typically, this distribution is a multivariate Gaussian distribution with a diagonal covariance matrix and mean vector. The encoder network comprises multiple layers that gradually reduce the input data’s dimensionality until it reaches the desired latent variable size.
The decoder reconstructs the output space using a sample from the latent distribution. The decoder network comprises an array of layers that gradually expand the latent variable’s dimension until it equals the size of the initial input data. The decoder’s output is a reconstruction of the original input.
The VAE learns during training to minimize the discrepancy between the input and the reconstructed output and the separation between the latent variable and a typical normal distribution.
Generative Adversarial Networks (GANs): Generative Adversarial Networks (GANs consist of two networks: a discriminator and a generator. When the discriminator learns to distinguish between actual and fabricated data, the generator provides fresh examples of data. In a process known as adversarial training, the two networks are trained at random so that the generator may learn to produce data that will deceive the discriminator, and the discriminator can learn to discern between real and fake data properly. The fundamental principle of GANs is that the generator creates data out of a random noise vector, which is then fed through several layers to create a new data sample. The discriminator generates a probability after determining if a data example is real or fake. The discriminator tries to discern between real and fake data, while the generator seeks to create data that appears real to the discriminator during training.

A generator loss and a discriminator loss are two loss functions that must be minimized during the training process. The discriminator loss evaluates how well the discriminator can discriminate between real and bogus data, whereas the generator loss measures how well the generator can deceive the discriminator. For the generator to provide realistic data and for the discriminator to accurately tell the difference between genuine and false data, it is necessary to balance these two loss functions.
Deep Belief Networks (DBNs): Several layers of neurons make up Deep Belief Networks (DBNs), a form of Artificial Neural Network (ANN). DBNs are used for tasks requiring unsupervised learning, such as dimensionality reduction, pattern recognition, and feature learning. They comprise layered Restricted Boltzmann Machines (RBMs), which are trainable with a Contrastive Divergence algorithm variation.
The fundamental principle of a DBN is that, by building on the features learned by the previous layer, each layer of neurons learns to represent higher-level properties of the input data. The input data is fed into the DBN’s first layer, which learns basic features, and the second layer then learns a collection of higher-level features using the output of the first layer as input.
Restricted Boltzmann Machines (RBMs) can learn to represent the probability distribution of the input data, and they are utilized in DBNs. RBMs are trained to reconstruct their inputs from noisy copies of the inputs during training. This is accomplished by adjusting the RBM’s weights to increase the likelihood of the input data given the RBM model. The layers of the DBN can be improved using supervised learning once the RBMs have been trained to increase their capacity for output data classification or prediction.
DBNs have been effectively used for various applications, including drug discovery, audio and picture recognition, and natural language processing. Moreover, they have been utilized for deep neural network unsupervised pre-training, which has been demonstrated to enhance the performance of supervised learning algorithms on many tasks.
Recurrent Neural Networks (RNNs): Recurrent Neural Networks (RNNs) are a subclass of Artificial Neural Networks designed to deal with sequential input, like time series or text data. The fundamental principle of RNNs is to employ feedback loops to enable the network to preserve a “memory” of prior inputs. This makes the network suitable for jobs like language modeling, speech recognition, and machine translation since it allows the network to represent the temporal connections between components in a sequence. The “cell” receives the current element in the sequence as input, and the network’s prior hidden state is the fundamental unit of an RNN. The cell then uses the input and the previous hidden state to compute a new hidden state and an output. The network may gather data from earlier parts in the sequence thanks to the hidden state, which functions as its “memory.” The output can be used to make predictions or re-input into the network. The RNN adjusts the hidden state by the output by using it as input for the following time step. As a result, the RNN can include data from earlier time steps in its present output.
The parameters of the RNN are changed during training to reduce a loss function that calculates the discrepancy between the predicted and actual output. Backpropagation through time (BPTT) is a common technique for accomplishing this. BPTT calculates the gradients of the loss function concerning the parameters of the RNN at each time step and updates the parameters as necessary.
Transformer Models: Transformer Models are neural network architecture generally used for text summarization and translation tasks involving natural language. The fundamental idea behind a Transformer is to enable the model to focus on various elements of the input sequence rather than processing them sequentially, as is the case with conventional Recurrent Neural Networks (RNNs). This is made possible through a mechanism known as self-attention, which enables the model to weigh the significance of various input sequence components when producing each output. An encoder and a decoder are the two primary parts of the Transformer. When it processes the input sequence, the encoder creates several hidden representations, each containing data on a distinct sequence section. Using an auto regression technique, the decoder gradually uses these hidden representations to produce the output sequence.
Each layer of the encoder and decoder consists of two sub-layers: a multi-head self-attention layer and a feedforward neural network. The self-attention layer converts the input sequence into a set of queries, keys, and values. These values are then used to compute a weighted sum, with the weights being based on how similar the queries and keys are. As a result, depending on the situation, the model might concentrate on various elements of the input sequence. After performing a non-linear transformation on the output of the self-attention layer, the feedforward neural network passes it on to the following layer. This makes capturing input and output sequences’ more intricate interactions easier.
Overall, the Transformer model outperforms conventional RNN-based models in several ways, including improved parallelization, more effective training, and the capacity to handle longer input sequences. It has emerged as the standard architecture for many NLP tasks and has been used to produce cutting-edge results on various benchmarks.
Each type of generative AI has its strengths and weaknesses, and the choice of which one to use depends on the specific application and the type of data being generated.
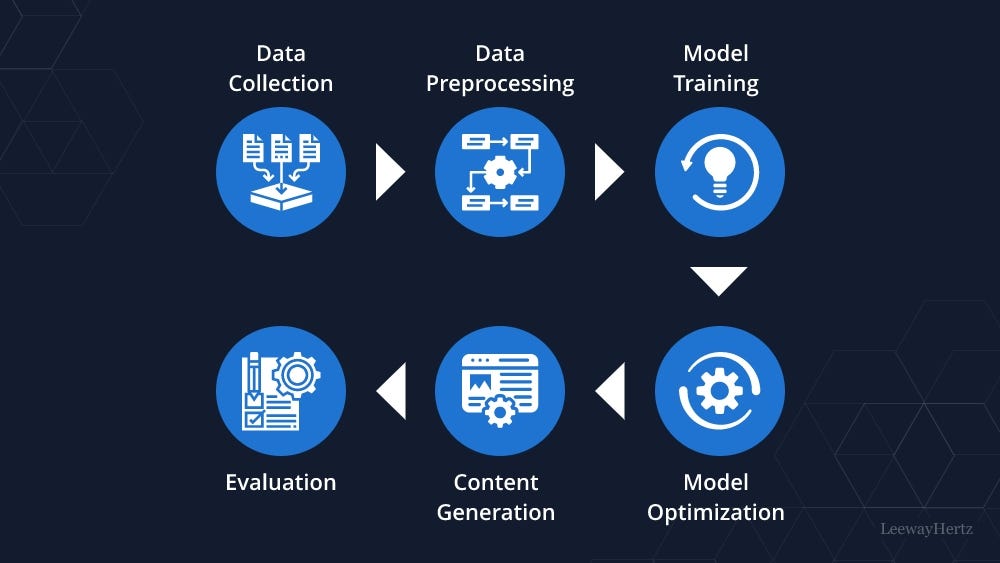
Creating a generative AI solution can be time-consuming and entail several processes, from prototyping to production. Here is a thorough guide to assist you in creating a generative AI solution from scratch:
Defining the problem: The objective of this stage is to precisely define the issue that generative AI will be used to address. This entails pinpointing a particular area where generative AI can enhance an already-existing procedure or produce something entirely new. This stage is crucial because it establishes the groundwork for the succeeding steps in the process and aids in providing a defined aim for the generative AI model. To ensure that the generative AI solution is directed toward the correct objective, the problem formulation should be clear, simple and exact.
Researching and choosing a generative AI algorithm: This stage involves finding and selecting a generative AI algorithm appropriate for the problem identified in the previous step. Various generative AI algorithms have varied advantages and disadvantages, and some jobs may suit them better. For instance, a VAE is better suited for producing images or videos, whereas a language model like GPT-3 excels at producing text. Nonetheless, a GAN is especially helpful for producing high-quality photos, movies, or music. The most appropriate algorithm should be chosen based on the specifics of the problem it is trying to solve and the desired results. Select an algorithm that generates effective and efficient outputs in meeting the project requirements.
Gather and preprocess data: The data that will be utilized to train the generative AI model must be gathered and prepared in this step. This entails gathering data pertinent to the issue and ensuring it’s accurate, reliable, and high-quality. Depending on the issue, this data may consist of text, photos, audio, or other data. Preprocessing the data is essential because it removes noise, extraneous data, and inconsistencies that could produce biased or erroneous conclusions. Cleaning the data, eliminating duplication, removing stop words, stemming or lemmatizing words, and tokenizing the data are some important preprocessing steps. For the generative AI model to identify patterns and provide reliable results, ensuring the dataset is large and diverse enough is critical. The data is prepared for use in training the generative AI model once it has been gathered and preprocessed.
Prototyping the solution: To build a prototype of the solution, select the generative AI algorithm and the preprocessed data in this stage. This entails fine-tuning the model until it yields acceptable results after training it on the preprocessed data. The model gains the ability to spot patterns in the data during training and produce results based on those patterns. To improve the model’s performance, we might need to test various hyperparameters like learning rate, batch size, and the number of epochs. Following model training, it can produce sample outputs and assess them to see if they satisfy the criteria. It might require iteration on the model and training procedure until satisfactory results are achieved.
Testing and refining the model: In this step, the model must be tested, assessed, and any necessary adjustments must be made to it. This entails creating sample outputs and assessing their quality, coherence, and applicability. If the results are unsatisfactory, update the technique, add new data, or tweak the model’s parameters. For instance, if the results are not cohesive, the model’s architecture or the data preprocessing procedures might be changed. It may require more data or a change in the algorithm if the outcomes are not diverse enough. Conducting rigorous testing and improvement to ensure that the generative AI model generates high-quality outputs that satisfy the criteria is crucial. This procedure might include multiple iterations of testing, refining, and retraining the model until we achieve satisfactory results.
Building a production-ready solution: The goal of this last step is to create a production-ready solution that is fast, scalable, and reliable. This involves developing a deployable system that can produce outputs in real-time or very close to real-time from the improved prototype. This may need technologies like distributed computing, cloud-based infrastructure, or containerization to speed up processing and deployment. The architecture and parameters of the model may also need to be optimized for effectiveness and scalability to ensure that the solution is stable and dependable in real-world settings. After the solution is ready for production, it can be deployed to the target environment and extensively test it to ensure it satisfies the needs. This might require monitoring the solution’s effectiveness and making modifications as necessary.
Testing and optimizing the solution: This step involves testing the generative AI solution in a real situation and refining it in light of user feedback and performance data. This entails implementing the solution and getting user input to assess its effectiveness and quality. Based on the feedback and performance metrics, there might be a need to refine the design, change some settings, or update the algorithm. Until the desired outcomes are achieved, this process of optimization and refining may require several iterations. To ensure that the solution remains applicable and efficient throughout time, it is crucial to analyze its performance and user feedback regularly. This may entail routine updates, bug corrections, or feature additions to enhance the functionality and user experience of the solution.
Deploying and maintaining the solution: Once the generative AI solution has been tested and optimized, deploy it in a production environment and maintain it over time to ensure it continues performing well. This could involve monitoring the system for errors, updating the algorithm to improve performance, or adding new features to meet evolving user needs.
Always remember that developing a generative AI solution is an iterative process that necessitates continuous progress. You may construct a potent instrument to produce new and creative content to tackle various problems by using these methods and continually reviewing and improving your answer.
Generative AI offers several benefits to businesses, such as:
Enhancing creativity: Generative AI can provide original and fresh concepts, layouts, and solutions that might not have been possible with more conventional techniques. This can help companies stay one step ahead of the competition and provide clients with innovative products or services.
Improving efficiency: Generative AI may automate tedious jobs like data input and analysis, freeing staff members to work on more challenging and innovative projects.
Personalizing customer experience: Generative AI can evaluate vast volumes of consumer data to produce recommendations and experiences tailored to users’ needs and behavior.
Predicting trends: Generative AI can evaluate information from various sources, including social media, to spot new patterns and trends. This allows companies to stay ahead of the curve and modify their plans as necessary.
Reducing costs: Generative AI is used to streamline processes and cut waste, thereby reducing costs.
Ultimately, generative AI can transform businesses’ operations by fostering greater productivity, efficiency, and innovation.
We are at the dawn of a new era where generative AI powers businesses and boosts growth. After all, businesses have already begun using generative AI’s extraordinary power to install, maintain, and monitor complex systems with unmatched simplicity and effectiveness. By utilizing this cutting-edge technology to its fullest capacity, organizations can make better judgments, take prudent risks, and remain flexible in the face of quickly shifting market conditions. The applications of generative AI will increase and become more vital to our daily lives as we continue to push the technology’s limits. With generative AI, companies can achieve previously unattainable levels of creativity, efficiency, speed, and accuracy, giving them an unrivaled advantage in today’s fiercely competitive market. The infinite possibilities range from banking, logistics, and transportation to medical and product development. It’s time to embrace the generative AI revolution and unleash this amazing technology’s full potential. Doing so can open the door to a brand-new era of business success and solidify your position as an industry leader in innovation and development.
[ad_2]
Source link








{kind=link}